

Welcome to our latest FAQ Friday — data lakes FAQ — where industry experts answer your burning technology and startup questions. We’ve gathered top Minnesota authorities on topics from software development to accounting to talent acquisition and everything in between. Check in each week, and submit your questions here.
This week’s FAQ Friday is sponsored by Coherent Solutions. Coherent Solutions is a software product development and consulting company that solves customer business problems by bringing together global expertise, innovation, and creativity. The business helps companies tap into the technology expertise and operational efficiencies made possible by their global delivery model.
Meet Our FAQ Expert
Max Belov, CTO of Coherent Solutions

Max Belov
Max Belov has been with Coherent Solutions since 1998 and became CTO in 2001. He is an accomplished architect and an expert in distributed systems design and implementation. He’s responsible for guiding the strategic direction of the company’s technology services, which include custom software development, data services, DevOps & cloud, quality assurance, and Salesforce.
Max also heads innovation initiatives within Coherent’s R&D lab to develop emerging technology solutions. These initiatives provide customers with top notch technology solutions IoT, blockchain, and AI, among others. Find out more about these solutions and view client videos on the Coherent Solutions YouTube channel.
Max holds a master’s degree in Theoretical Computer Science from Moscow State University. When he isn’t working, he enjoys spending time with his family, on a racetrack, and playing competitive team handball.
This Week’s FAQ Topic — Data Lakes
Let’s start simple — What are data lakes? What is data warehouse?
Data lakes are centralized data repositories that are capable of securely storing large amounts of data in a variety of its native formats. It allows to consumers to search for relevant data in the repository and query it by defining the structure that makes sense at the time of use. In simple terms, we don’t really care what format data has when we capture and store it. Format only becomes relevant when we start to analyze the data and can therefore use the same source data for new types of analysis as the need arises. There are a variety of tools and techniques one can use to implement efficient data lakes.
A data warehouse is similar to data lakes in that it is also capable of storing and making available for analysis large volumes of data. However, this is where similarities end. A data warehouse typically has stricter data architecture and design that needs to be defined before you start populating it with data. A data warehouse uses relational representation of your data and the data in the repository needs to be structured according to how you are planning to use it in the future. While feeding data from your data warehouse into purpose-built data marts may add flexibility to the solution, a significant re-architecture effort may be required to add additional data types to a data warehouse or to support new types of data analysis.
A data warehouse can be used to complement a data lake. You would land data in a data lake, perform initial analysis, and then send the data to a data warehouse designed for a certain business or data domain.
Here is an easy comparison between data lake and data warehouse.
| Data Warehouse | Data Lake | |
| Data | Regional Data | Structure, Semi-structured, Unstructured data |
| Data Quality | Highly curated data, source of truth | Raw data |
| Schema | Most often designed prior to implementation (Schema-on-write) | Defined at the time of analysis (schema-on-read) |
| Users | Business users, data developers | Data scientists, data developers, data engineers, data architects |
| Usage | Reporting, Business Intelligence, Visualization | Exploratory Analysis, Discovery, Machine Learning, Profiling |
How do you know if your business is right for data lake or data warehouse, and how can it be a benefit?
A data lake architecture enables organizations to handle ever increasing data volumes, varieties, and velocities, while continuing to provide security, ability to consistently process and govern the data. A single repository can then service many different types of analytics workloads such as visualizations, dashboards, and machine learning.
A data lake enables the business to introduce additional use cases for the data without impacting existing ones. It also provides separation between storage and compute thus ensuring that different applications that consume the data will have minimal impact on each other.
So, what does a successful implementation of a data lake looks like?
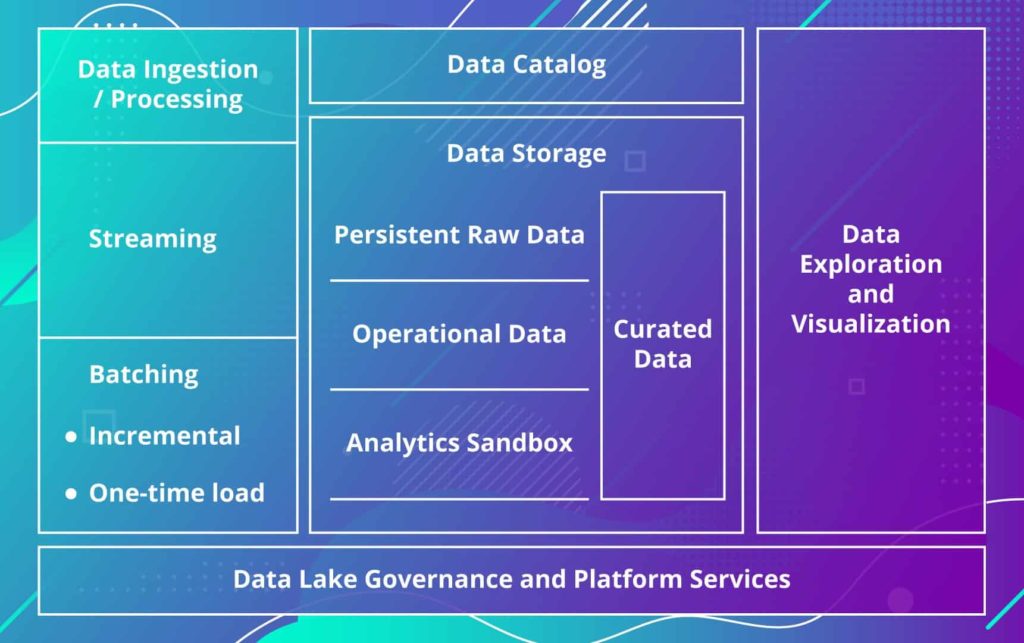
There are five key pillars of a successful data lake solution:
- Data Ingestion/Processing Mechanism: Proper selection allows you to properly support expected volume of the data and its velocity (how much data you have to begin with and how quickly the new data is coming in).
- Data Catalog: This is what keeps your data lake a lake, not a swamp. It provides the metadata describing the content of your data lake — the meaning of various data within it.
- Data Storage: Your data lake is not a single centralized storage bucket. There’s a logical and physical structure that helps you break data by your processing lifecycle (raw vs cleansed), by the type of a source system it is coming from, by how you intend to use it (since its final data format and representation may vary), and also depending on the analysis you are trying to perform, etc.
- Data Lake Governance and Platform Services: This is the glue that holds everything together starting from infrastructure management (provisioning, monitoring, scheduling), data quality (ensuring provided data is a reliable fit for the intended purpose within the enterprise) and data lineage (understanding where the data is coming from to data security, how it changes/evolves as it moves from the source into the data lake and through data lake) to data security (controlling data access and preventing breaches through implementing appropriate network and access control mechanisms, and end-to-end encryption of the data).
- Data Exploration and Visualization: You should define which groups within the company are going to be the consumers of data from the data lake and carefully examine their real (not just declared) needs, consumption scenarios, analytical proficiency and currently used toolset. Proper selection of Data Exploration and Visualization component is the key to user adoption and therefore the success of the overall endeavor.
From the implementation perspective, there are some key decisions that need to be made.
Where you are going to host your data? This can be within your own data center or within one of the public cloud providers. The actual technical solution you develop may be portable across different providers, but once you deploy it and start accumulating data, you will be locked in since migrating large amounts of data from one platform to another may prove to be a very expensive proposition if you decide to change providers.
What data storage technology will you use? Choosing optimal solutions will help you balance durability and scale data access throughput, security (access audit, encryption at rest and transit), and cost efficiency.
Hungry for more information on Data Services? Visit Coherent Solutions.
Still curious? Ask Max and the Coherent Solutions team questions on Twitter at @CoherentTweets.
![]()
Don’t stop learning! Get the scoop on a ton of valuable topics from Max Belov and Coherent Solutions in our FAQ Friday archive.



